今天给各位分享bulkupdate的知识,其中也会对bulkUpdate方法作用进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:
- 1、Hibernate的批量处理
- 2、mysql怎么设置bulk
- 3、关于请问SqlBulkCopy有Update功能吗
- 4、线上es报错异常分析
- 5、Elasticsearch数据迁移与集群容灾
- 6、如何实现大数据量数据库的历史数据归档
Hibernate的批量处理
1、Session.save()方法:Session.save()方法用于实体对象的持久化保存,也就是说当执行session.save()方法时会生成对应的insert SQL语句,完成数据的保存。
2、不适合批量操作。Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
3、你的hibernate.cfg.xml中加入了WebRolepopedom.hbm.xml映射文件没?一般都是try{}catch(Exception e){}finally{} 你trycatch之间加入代码似乎不妥。把那之间的代码加入finally中去。catch中也没有回滚。
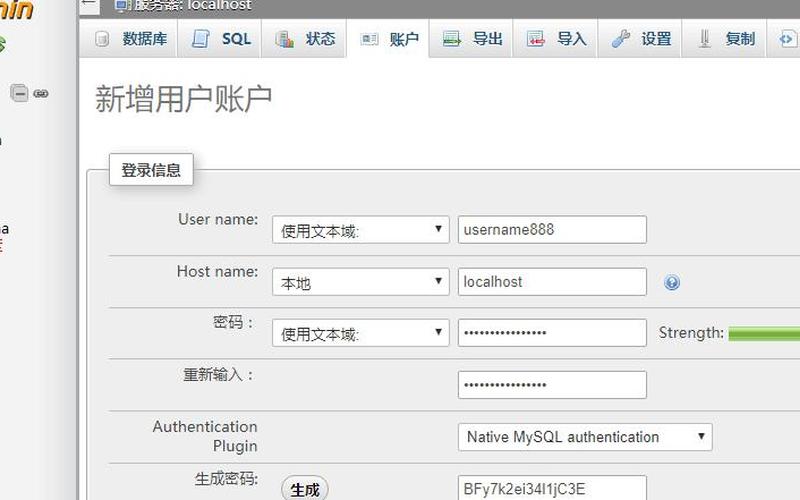
mysql怎么设置bulk
举例:bulk_insert_buffer_size=100M;第二种mysql插入提速方法:改写所有 insert into 语句为 insert delayed into 这个insert delayed不同之处在于:立即返回结果,后台进行处理插入。
BulkCopy的原理就是Client直接把一个数组(DataTable)传给DB,然后传入表名,所有的编译、操作都由DB自己完成,效率很高。引用MySql.Data.dll , 调用MysqlBulkCopy函数即可。
先需要安装MySQL数据库,修改MySQL的配置文件启用中文界面。配置文件位于MySQL的安装目录下的myini(Windows)或mycnf(Linux)文件中,保存并关闭配置文件。重启MySQL服务,使修改的配置生效即可。
测试数据5G,共有数据9427567条。用的mysql的large服务器的配置。load 一次需要大概10分钟左右。
关于请问SqlBulkCopy有Update功能吗
那么现在就介绍一下两种方法,一种是SqlDataAdapter的Update(dataTable)方法,另一种是SqlBulkCopy类。
SqlBulkCopyColumnMappingCollection 继承自 CollectionBase 的 SqlBulkCopyColumnMapping 对象的*。SqlClientFactory 表示一组方法,这些方法用于创建 System.Data.SqlClient 提供程序对数据源类的实现的实例。
这是做不到的,除非ID不是标识。其实在数据库设计的时候不应该对ID赋予某种含义,如果ID没有含义,那它是几又有什么关系呢。
可以,需要使用Transaction登记,给你我以前写的批量导入代码,我稍微修改了一下。
*用户还能够通过创建有一个或多个要复制的DataTable的运行时间DataSet来从表格化XML文档中插入行。用SqlBulkCopy将XML文档批量复制到SQL Server表(此过程称为分解)要比SQLXML 0的批量加载功能简单得多。
线上es报错异常分析
1、其实这个就是JSON格式化错误。解决方法:就是检查生成的JSON字符串格式是否正确。
2、更新应用程序:确保您使用的是最新版本的ES文件浏览器应用程序。您可以通过应用商店或官方网站下载并安装最新版本。清除缓存:在设备的应用设置中找到ES文件浏览器,并尝试清除应用的缓存数据。这通常可以解决一些常见的错误。
3、农行网捷贷报错ES369代表什么意思?1ES369代表借款人的授信*不足,无法完成借款申请。2这种情况可能是因为借款人的信用评级较低,或者已经使用了较大比例的授信*,导致当前无法再次借款。
4、具体到 RIPES 软件,出栈入栈报错可能还与以下原因有关:RIPES 软件版本不兼容:如果 RIPES 软件版本与打印机驱动程序版本不兼容,则可能导致出栈入栈报错。
Elasticsearch数据迁移与集群容灾
1、reindex是Elasticsearch提供的一个api接口,可以把数据从一个集群迁移到另外一个集群。
2、Elasticsearch使用可以简单分为两个阶段。数据初始化阶段、数据更新阶段。数据初始化阶段。数据初始化常见的方式如下:通过应用程序手动将数据库中的数据,调用ES接口API插入ES索引库中。
3、es水平扩容数据有丢失风险。根据查询相关资料信息,Elasticsearch是利用分片将数据分发到集群内各节点。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。
4、关系型数据库MySQL:MySQL在迁移中最为常见,也有很成熟的迁移工具和迁移方案,包括官方工具和相关开源工具,如mysqldump等,各个云厂商也都有各自的DTS迁移工具。
5、Elasticsearch由一些Elasticsearch进程(Node)组成集群,用来存放索引(Index)。为了存放数据量很大的索引,Elasticsearch将Index切分成多个分片(Shard),在这些Shard里存放一个个的文档(document)。通过这一批shard组成一个完整的index。
如何实现大数据量数据库的历史数据归档
指定通过WHERE条件语句指定需要归档的数据,该选项是必须指定的选项。不需要加上WHERE关键字,如果确实不需要WHERE条件进行限制,则指定--where 1=1。--file 指定表数据需要归档到的文件。
时间维度分区表,然后定情按照规则将属于历史的分区数据迁移到,历史库上,写个存储自动维护分区表。
迁移至历史表:将历史数据迁移至独立的历史表中,只保留最近的数据在主表中。这种方式适用于历史数据的读取需求较高,而且主表的数据量较大,影响查询性能。
一)降低成本。将数据按时从业务系统分离出来归档,使得企业IT系统运行、维护、投入整体成本降低。(二)缩短备份时间。由于数据增长太快,即便备份人员使用了数据压缩和重复数据删除技术备份数据,往往还是会遇到备份窗口的压力。